
GPT-5ベンチマーク問題現実性能
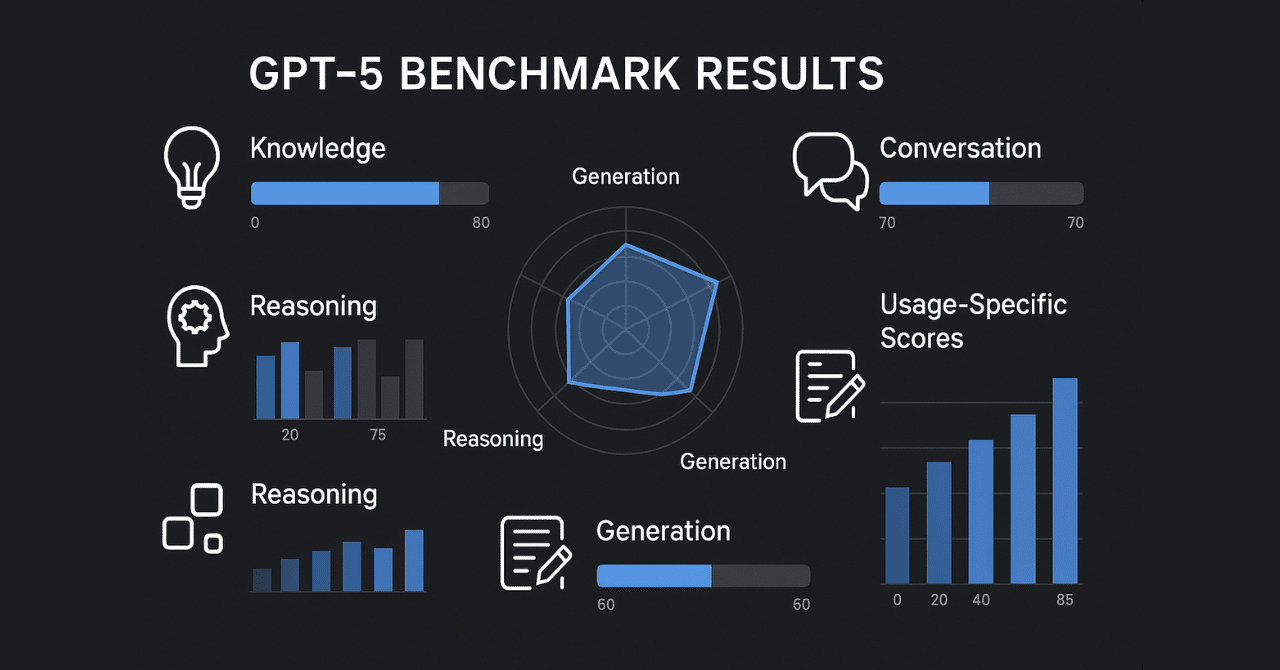
GPT-5は、OpenAIが2025年8月にリリースした最新のAIモデルです。このモデルは、数学やコーディング、マルチモーダル理解などのベンチマークで高いスコアを記録し、従来のモデルを上回る性能を示しています。例えば、AIME 2025では94.6%、SWE-bench Verifiedでは74.9%、MMMUでは84.2%という結果です。しかし、現実の現場ではベンチマークの数字だけでは測れない課題も指摘されています。安定性や実際の業務適用でのギャップが議論されており、ユーザーはより実用的な評価を求めています。この記事では、ベンチマークの概要と現実性能の問題点を詳しく見ていきます。
ベンチマークスコアの概要
GPT-5は、さまざまな分野で優れた結果を出しています。数学の難問ではツールなしで高精度を達成し、コーディングでは実務レベルのタスクを効率的に処理します。マルチモーダル能力も進化し、画像や動画の理解が向上しています。これにより、複雑な推論問題やアプリ生成が1回のプロンプトで可能になりました。
-
数学分野では、AIME 2025で94.6%を記録。従来モデルより明確に優位です。
-
コーディングでは、SWE-bench Verifiedで74.9%。実世界のソフトウェア開発に強い。
-
マルチモーダルでは、MMMUで84.2%。複数ツールの連携がスムーズになりました。
現実運用での課題
現場での使用では、ベンチマークの高スコアが必ずしも実用性を保証しない点が問題視されています。平均スコアが高い一方で、出力のばらつきや安定性が不足する場合があります。評価手法も曖昧で、プロンプトの違いで結果が変わるため、業務での信頼性が課題です。また、モデル規模の拡大だけでは限界があり、論理的思考の強化が求められています。
-
実務では、成功率の安定性が重要。複数回の試行が必要になるケースがあります。
-
AIによる自動評価は、判定の曖昧さがネック。人間の介入を減らす工夫が必要です。
-
専門分野では、期待とのギャップが目立つ。安全性や効率のバランスが鍵です。
まとめ
GPT-5はベンチマーク上で顕著な進化を遂げていますが、現実の運用では新たな課題が浮上しています。数学やコーディングでの高スコアは魅力的ですが、現場の声では「テストでは優秀でも実務で微妙」という指摘が多く、評価手法の限界が明らかになりました。トレース評価のようなプロセス全体を測る方法が注目され、成功率やコストを考慮した実用的な基準が重要視されています。これにより、AIの真の価値がより正確に判断できるようになるでしょう。全体として、GPT-5は潜在力が高い一方で、安定性と実務適合性の向上が今後の焦点です。
-
ベンチマークは参考にしつつ、実務テストを試してみてね。
-
安定した出力が欲しい時は、プロンプトを工夫するのがおすすめ。
-
専門分野での活用は、事前の検証が欠かせないよ。
結論
GPT-5はAIの新たなスタンダードを確立しつつありますが、ベンチマークの数字を超えた現実性能の向上が求められます。ユーザーの皆さんが実際に使ってみて、その強みと弱みを体感するのが一番です。ガジェット好きとして、この進化を楽しみながら、賢く活用していきましょう。きっと、日常の作業がもっと効率的になるはずです。
